Modern Data Stack 2025: Complete Guide for $10/Month | Data Engineering Solutions
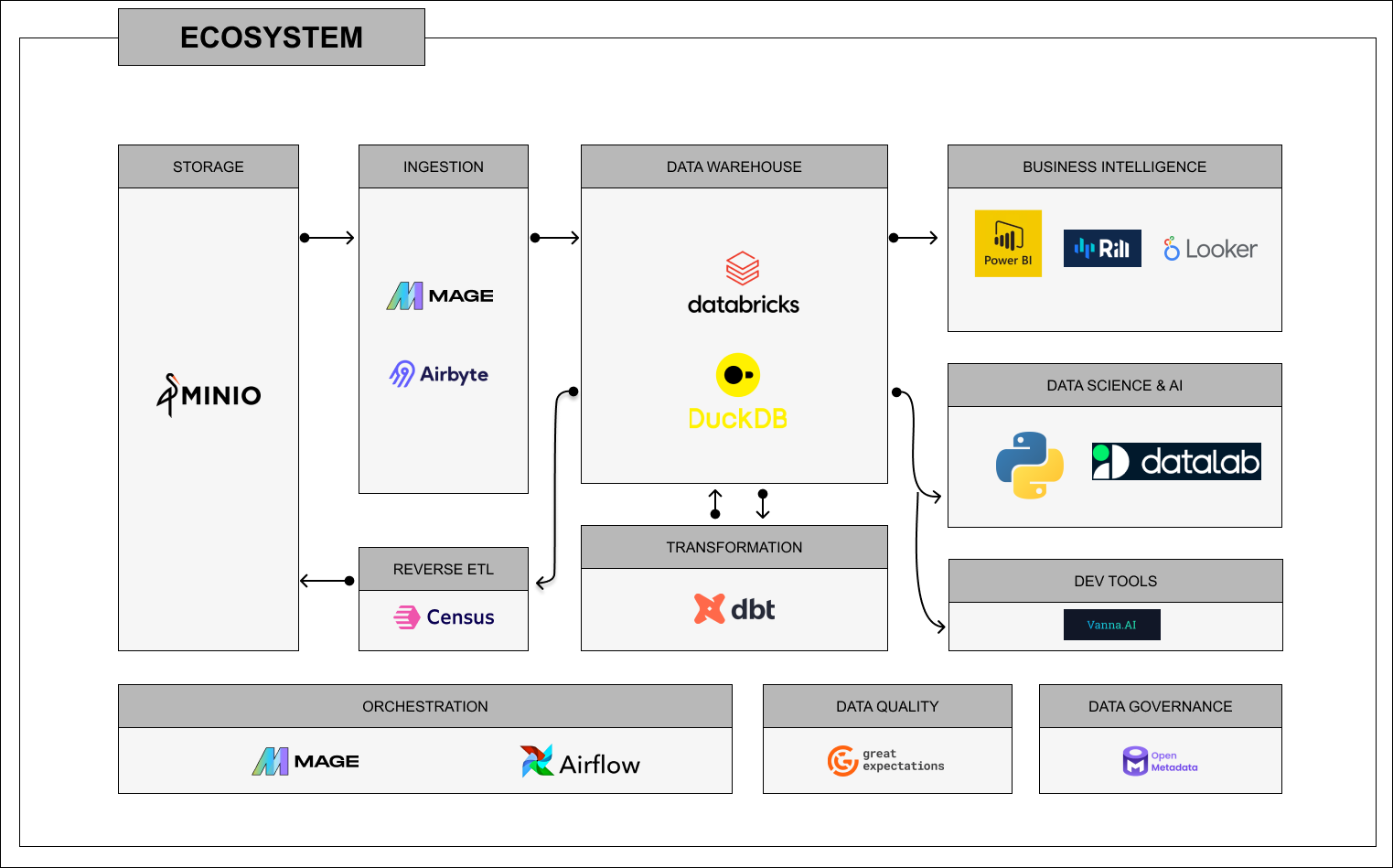
As data engineering specialists in the Stockholm area, we’ve helped companies build cost-effective data stacks that deliver enterprise-quality solutions for a fraction of traditional costs. This comprehensive guide on modern data stack engineering shares exactly how to build a modern data stack for only $10/month. For more on data engineering and AI automation, see my complete portfolio of solutions.
What is a Modern Data Stack?
A modern data stack is a collection of cloud-native tools that work together to:
- Collect data from various sources
- Transform and model data for analysis
- Visualize insights for decision-making
- Automate workflows for scalability
Why “Modern”?
Unlike legacy systems, modern data stacks are:
- ✅ Cloud-native - no infrastructure management
- ✅ Serverless - pay only for what you use
- ✅ SQL-first - familiar to most analysts
- ✅ Version-controlled - code your data logic
Unified Data Architecture: Why It Matters
A unified data architecture means all your data sources, transformations, and analytics live in one coherent system instead of scattered spreadsheets and siloed databases. The modern data stack approach delivers exactly that: a single pipeline from raw data to actionable insights, with one source of truth and consistent governance. Whether you’re running Snowflake + dbt or scaling to a full lakehouse, the goal is the same—unify your data so every team works from the same foundation.
The Complete $10/Month Architecture
Core Components (Total: ~$10/month)
1. Data Warehouse: Snowflake (~$5/month)
-- Create your first table
CREATE TABLE customer_analytics (
customer_id INT,
order_date DATE,
revenue DECIMAL(10,2),
region VARCHAR(50)
);Why Snowflake:
- Automatic scaling
- Separated compute/storage
- Excellent performance for small datasets
2. Data Transformation: dbt Core (Free)
# models/customer_metrics.sql
SELECT
region,
DATE_TRUNC('month', order_date) as month,
COUNT(DISTINCT customer_id) as unique_customers,
SUM(revenue) as total_revenue
FROM {{ ref('customer_analytics') }}
GROUP BY 1, 23. Orchestration: GitHub Actions (Free)
name: Data Pipeline
on:
schedule:
- cron: '0 6 * * *' # Daily at 06:00
jobs:
run_dbt:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Run dbt
run: |
dbt deps
dbt run
dbt test4. Visualization: Metabase (~$5/month on DigitalOcean)
- Open source BI tool
- Easy to deploy
- Powerful dashboards
Implementation Guide: Step-by-Step
Step 1: Set up Snowflake (15 minutes)
# 1. Register free Snowflake account
# 2. Create warehouse with AUTO_SUSPEND=60
CREATE WAREHOUSE dev_wh
WITH WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60;
# 3. Create database and schema
CREATE DATABASE analytics;
CREATE SCHEMA analytics.staging;Step 2: Install dbt (10 minutes)
# Install dbt-snowflake
pip install dbt-snowflake
# Initialize project
dbt init my_data_project
cd my_data_project
# Configure connection
# ~/.dbt/profiles.yml
my_data_project:
target: dev
outputs:
dev:
type: snowflake
account: YOUR_ACCOUNT.eu-west-1
user: YOUR_USERNAME
password: YOUR_PASSWORD
role: ACCOUNTADMIN
database: ANALYTICS
warehouse: DEV_WH
schema: stagingStep 3: First Data Pipeline (20 minutes)
-- models/staging/stg_orders.sql
SELECT
order_id,
customer_id,
order_date::DATE as order_date,
amount::DECIMAL(10,2) as amount,
status
FROM {{ source('raw', 'orders') }}
WHERE order_date >= '2024-01-01'-- models/marts/customer_summary.sql
SELECT
customer_id,
COUNT(*) as total_orders,
SUM(amount) as lifetime_value,
MAX(order_date) as last_order_date
FROM {{ ref('stg_orders') }}
GROUP BY customer_idSteg 4: Automatisering med GitHub Actions
# .github/workflows/data_pipeline.yml
name: Daily Data Pipeline
on:
schedule:
- cron: '0 6 * * *'
jobs:
run_pipeline:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install dbt-snowflake
dbt deps
- name: Run dbt pipeline
env:
DBT_PROFILES_DIR: .
run: |
dbt run --target prod
dbt test --target prodKostnadsuppdelning & Optimering
Månadsvis Kostnadskalkyl
| Komponent | Kostnad | Kommentar |
|---|---|---|
| Snowflake | $2-8 | Beroende på användning |
| Metabase (DigitalOcean) | $5 | Droplet $5/månad |
| dbt Core | Gratis | Open source |
| GitHub Actions | Gratis | 2000 minuter/månad |
| Total | $7-13 | Genomsnitt $10 |
Optimeringstips för Kostnadskontroll
-- 1. Använd AUTO_SUSPEND för warehouses
ALTER WAREHOUSE dev_wh SET AUTO_SUSPEND = 60;
-- 2. Schemalägg tunga queries under lågtrafik
-- 3. Använd CLUSTERING för stora tabeller
-- 4. Monitorer QUERY_HISTORY för kostnadsdrivare
SELECT
query_text,
total_elapsed_time/1000 as seconds,
credits_used_cloud_services
FROM table(information_schema.query_history())
WHERE start_time >= DATEADD(day, -7, CURRENT_TIMESTAMP())
ORDER BY credits_used_cloud_services DESC
LIMIT 10;Svenska Företag & GDPR Compliance
Datahantering enligt GDPR
-- Implementera data retention policies
CREATE TABLE customer_data_retention (
customer_id INT,
consent_date DATE,
retention_period INT -- dagar
);
-- Automated deletion efter consent period
DELETE FROM customer_analytics
WHERE customer_id IN (
SELECT customer_id
FROM customer_data_retention
WHERE DATEDIFF(day, consent_date, CURRENT_DATE) > retention_period
);Svenska Molnregioner
För svenska företag rekommenderar jag:
- Snowflake EU-West-1 (Irland) för GDPR compliance
- Azure Sweden Central för extra säkerhet
- Dokumentera dataflöden för GDPR-audit
Hockey Analytics Case Study
Som expert på hockey analytics har jag implementerat denna stack för svenska ishockeylag:
-- Hockey performance metrics
WITH player_stats AS (
SELECT
player_id,
game_date,
goals,
assists,
shots_on_goal,
ice_time_seconds
FROM {{ ref('stg_game_logs') }}
),
performance_metrics AS (
SELECT
player_id,
AVG(goals + assists) as avg_points_per_game,
AVG(shots_on_goal) as avg_shots_per_game,
SUM(ice_time_seconds)/3600.0 as total_ice_time_hours
FROM player_stats
WHERE game_date >= DATEADD(month, -3, CURRENT_DATE)
GROUP BY player_id
)
SELECT * FROM performance_metrics
WHERE avg_points_per_game > 0.5 -- Filter for productive playersNästa Steg: Skalning & Advanced Features
När du växer över $10/månad budgeten:
- Lägg till Reverse ETL - Hightouch eller Census
- Implementera Data Quality - Great Expectations
- Advanced Orchestration - Prefect eller Dagster
- Real-time Processing - Kafka + ksqlDB
Professionell Support
Behöver du hjälp att implementera din moderna data stack? Som data engineer i Nacka erbjuder jag:
- Arkitektur-rådgivning för svenska företag
- Hands-on implementation av kompletta pipelines
- GDPR-compliance för europeiska regioner
- Hockey analytics specialisering
Sammanfattning
En modern data stack för $10/månad är inte bara möjlig - det är praktiskt för de flesta små till medelstora företag. Nyckeln är att:
- Starta enkelt med proven verktyg
- Automatisera tidigt för skalbarhet
- Monitera kostnader kontinuerligt
- Skala smart när behoven växer
Som data engineer i Stockholm-området har jag sett denna approach spara företag tusentals kronor månaden samtidigt som de får enterprise-kvalitet på sin data infrastructure.
Want to implement your own modern data stack? Contact me for personalized advice on data engineering, hockey analytics, or AI automation in the Stockholm area.
Emil Karlsson är data engineer och hockey analytics specialist baserad i Nacka, Sverige. Specialiserat på kostnadseffektiva data solutions för svenska företag.